Étant donné que nous disposons de trois variables d'entrée et d'une variable de
sortie, le nombre de neurones dans la couche cachée sera :
![]() soit 3
soit 3
![]() soit 75% de 3 c'est à dire 2.25. Donc 2 neurones.
soit 75% de 3 c'est à dire 2.25. Donc 2 neurones.
![]() soit
soit ![]() c'est à dire 1.73. Donc 1 neurone.
c'est à dire 1.73. Donc 1 neurone.
Notons que la variable zj de la couche cachée s'exprime par :
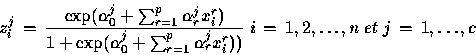
![]() Dans ce cas, le passage de la couche cachée à la variable de sortie est
linéaire.
Dans ce cas, le passage de la couche cachée à la variable de sortie est
linéaire.
On a donc :
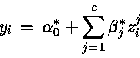
![]() Considérons d'abord le nombre de neurones dans la couche
cachée égal à deux et faisons varier la valeur du paramètre "decay".
Considérons d'abord le nombre de neurones dans la couche
cachée égal à deux et faisons varier la valeur du paramètre "decay".
Premier essai : decay=0.
> res11_nnet(temp1[,1:3],yy,size=2,decay=0,linout=T,maxit=100)En raison de redémarrages consécutifs de l'algorithme d'ajustement, avec différents points de départ aléatoires pour les poids, trois minima ont été trouvé : 131.59, 111.79 et 79.85.
# weights: 11 initial value 684.716345 final value 131.599985 converged # weights: 11 initial value 601.536740 iter 10 value 131.596179 iter 20 value 123.558993 iter 30 value 111.922908 iter 40 value 111.793906 final value 111.793888 converged # weights: 11 initial value 638.150206 iter 10 value 130.223657 iter 20 value 116.147958 iter 30 value 112.617872 iter 40 value 95.387017 iter 50 value 80.762905 iter 60 value 79.992882 iter 70 value 79.962711 final value 79.957258 convergedOn vérifie que la "Hessienne" est positive pour les trois minima afin de s'assurer qu'ils représentent bien des minima locaux.
Comparaison des valeurs prédites pour le troisième minimum avec la variable yy
> cbind(predict(res11,temp1[,1:3]),yy)
V1 yy
ajac 4.9198174 8.7
ango 4.9544435 4.9
besa 4.0312395 5.3
biar 4.9198174 2.0
bord 8.2998409 8.2
bres 4.9198174 6.2
cler 6.9975820 7.0
dijo 4.0312395 3.6
gren 4.0312395 2.1
lill 0.6690568 0.5
limo 4.9256830 2.3
lyon 4.0312467 3.5
mars 4.9198174 3.8
mont 4.9198174 3.1
nanc 4.0312395 6.9
nant 4.9198174 6.5
nice 4.9198174 1.8
orle 5.4199123 5.5
pari 8.2825470 8.2
perp 4.9198174 6.5
reim 3.6450274 3.6
renn 4.9198174 4.3
roue 4.9198198 8.6
stra 4.0312395 3.0
tlse 4.9198174 5.4
Ici, V1 représente le vecteur des valeurs prédites de yy à savoir les
températures du mois de décembre dans différentes villes de France. Il est
obtenu à l'aide de la commande "predict". La commande "cbind" nous permet de
concaténer par colonne les vecteurs yy et V1. summary(res11) a 3-2-1 network with 11 weights options were - linear output units 0->4 1->4 2->4 3->4 0->5 1->5 2->5 3->5 0->6 4->6 5->6 0.34 0.66 0.17 0.64 -0.23 -0.01 -0.16 -0.68 2.09 2.77 0.47Second essai : decay=0.001
Supposons maintenant qu'il existe un lien entre les variables d'entrée
et la variable de sortie.
Alors, le passage de la couche cachée à la variable de sortie s'écrit :
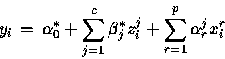
Pour un nombre quelconque de neurones cachés (inférieur ou égal à trois), on obtient
différents minima et les valeurs prédites pour les différents réseaux sont
aussi mauvaises.
Que peut-on donc en conclure ?
Comme on n'obtient pas les bonnes valeurs prédites, on peut donc émettre la conclusion
suivante à savoir que les températures des mois de janvier, avril et juillet
n'expliquent pas celles du mois de décembre.
Utilisation de l'option entropy et de l'option softmax
![]() Cas de l'option entropy
Cas de l'option entropy
Le passage de la couche cachée à la variable de sortie s'exprime par :
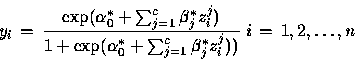
![]() Cas de l'option softmax
Cas de l'option softmax
Le passage de la couche cachée à la variable de sortie s'exprime par :
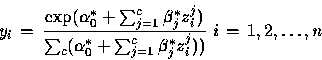
Dans ces deux formules, il n'y a pas d'influence des variables d'entrée.
![]() Avec ces deux options, les valeurs prédites valent toujours 1.
Avec ces deux options, les valeurs prédites valent toujours 1.
En effet, les valeurs prédites sont toujours comprises entre 0 et 1 même si les
valeurs observées de y sont négatives ou supérieures à 1.