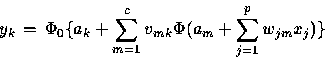Next: Comparaison de termes utilisés
Up: Réseau de neurones et
Previous: Le perceptron multicouches
On dispose d'une variable quantitative ou d'une variable qualitative (notée y)
à q modalités que l'on doit prédire à partir de p variables
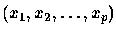 prédictrices. On dispose par ailleurs de n individus ou observations (échantillon
d'apprentissage) décrits par les p variables
et pour lesquels
ont connaît les valeurs de y. On suppose que la couche d'entrée est formée de p entrées, auxquelles seront
appliquées des coefficients appelés les poids synaptiques wjm. De plus,
il existe un terme constant en entrée qui, pour des raisons pratiques, prend
la valeur 1. La couche cachée comprend c neurones qui seront chacun activés
par une intégration (en général fonction monotone de la somme) des p signaux
en provenance de la couche d'entrée. La même opération a lieu pour les q éléments de la couche de sortie
mettant en jeu les poids synaptiques vmk. Il existe aussi une connexion
directe de l'entrée constante à la sortie.
prédictrices. On dispose par ailleurs de n individus ou observations (échantillon
d'apprentissage) décrits par les p variables
et pour lesquels
ont connaît les valeurs de y. On suppose que la couche d'entrée est formée de p entrées, auxquelles seront
appliquées des coefficients appelés les poids synaptiques wjm. De plus,
il existe un terme constant en entrée qui, pour des raisons pratiques, prend
la valeur 1. La couche cachée comprend c neurones qui seront chacun activés
par une intégration (en général fonction monotone de la somme) des p signaux
en provenance de la couche d'entrée. La même opération a lieu pour les q éléments de la couche de sortie
mettant en jeu les poids synaptiques vmk. Il existe aussi une connexion
directe de l'entrée constante à la sortie.
L'introduction de la constante d'entrée unitaire, connectée à chaque neurone
situé dans la couche cachée ainsi qu'à chaque sortie, évite d'introduire
séparément ce que les informaticiens appellent un biais pour chaque unité. Les
biais deviennent simplement parties intégrantes de la série de poids
(les paramètres).
En termes de modèle analytique, on écrira :
Dans cette formule, la fonction 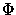 est la fonction logistique à savoir :
est la fonction logistique à savoir :
La fonction 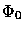 peut être selon les cas linéaire, logistique, ou à seuil.
peut être selon les cas linéaire, logistique, ou à seuil.
Remarquons que l'équation correspond à une observation (i). On a en réalité
n équations de ce type, faisant chacune intervenir q valeurs yk(i) et p
valeurs xj(i).
L'estimation des paramètres se fait en minimisant une fonction de perte, qui
peut simplement être la somme des carrés des écarts entre les valeurs calculées
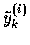 et les valeurs observées yk(i) dans l'échantillon
d'apprentissage.
et les valeurs observées yk(i) dans l'échantillon
d'apprentissage.
Next: Comparaison de termes utilisés
Up: Réseau de neurones et
Previous: Le perceptron multicouches
Yasmine yactine
1999-07-28